This chapter describes a variety of uses cases for replication. The use cases are accompanied by diagrams explaining the best way to accomplish replication in these scenarios.
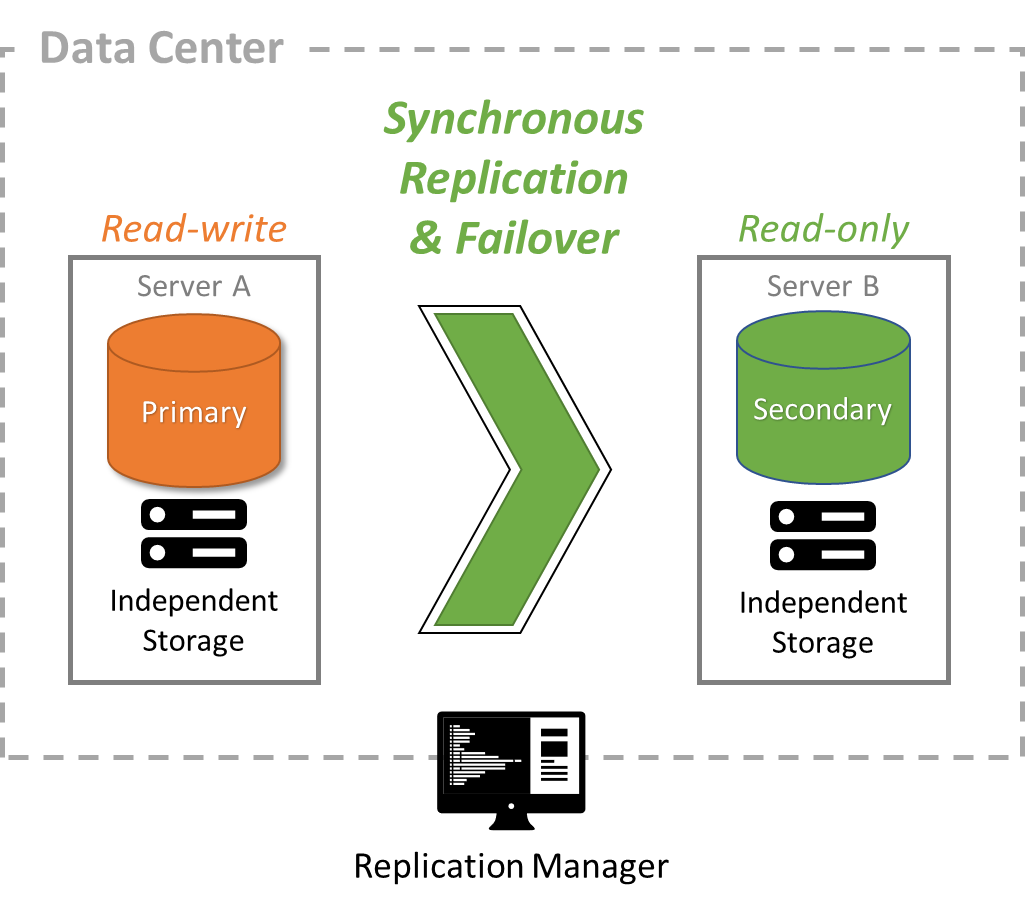
Automatic Operating System (OS) Failover leverages existing OS clustering solutions to detect hardware and software failures and properly fail over the database from a primary computer to a secondary. Replication V2 integrates with the proven clustering solutions built into Red Hat Enterprise Linux and Microsoft Windows Server. V2 makes it easy to cluster the database using OS clustering. STONITH support is also included to prevent “split brain” scenarios.
Use Case: Ideal for business continuity of multiple, mission-critical applications. It requires an operating system cluster to be installed and supported. It does not lose data and provides automatic failover. Individual transactions running at the time the primary server fails return an error and must be rerun.
Why:
To ensure high availability without data loss during failover
To use the read-only secondary server for reporting and analytics
How:
FairCom synchronous replication ensures both database servers always have the same committed data
OS clustering provides a virtual IP address that it controls to ensure applications can connect only to one database server at a time
OS clustering determines when to fail over by detecting hardware or software failure
OS clustering prevents a failed server from being accessed by clients, and, thus, prevents the possibility of inconsistent data
The OS notifies the secondary FairCom server of a failover. It applies all pending commit logs.
FairCom secondary server notifies all client applications of the failover event so they can reconnect to it
Automatic FairCom Database Failover
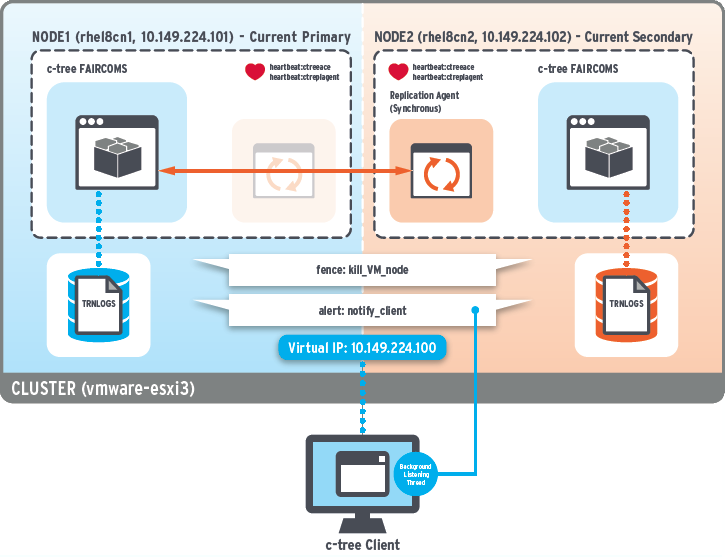
FairCom Database can be set up as a cluster of one or more servers (typically two or three). The database detects a failure of the primary database server and automatically fail over to a secondary database server. It does not require the operating system to provide clustering. This technology is available in FairCom’s fall 2020 release as a beta.
Use Case: Ideal for continuity of a single application. It does not require an operating system cluster to be installed and supported. It does not lose data and provides automatic failover. Individual transactions running at the time the primary server fails return an error and must be rerun. Because this approach does not use OS clustering, it does not guarantee that the failed database server will not receive connections after failover. If those connections modify data, a “split-brain” occurs and data becomes inconsistent. This solution is workable for a single application because it can ensure it connects to the proper database server.
Why:
To ensure high availability without data loss during failover
To use the read-only secondary server for application-specific use cases
How:
FairCom synchronous replication ensures all database servers in the cluster always have the same committed data
FairCom cluster detects a failure of the primary server and fails over to a secondary
The secondary server applies all pending commit logs
The secondary server notifies all client applications of the failover event so they can reconnect to it
The application must ensure it only writes to one server at a time to prevent the possibility of a split-brain scenario
The application may choose to use asynchronous replication on certain files for faster performance, when potential data loss during a failover is not an issue
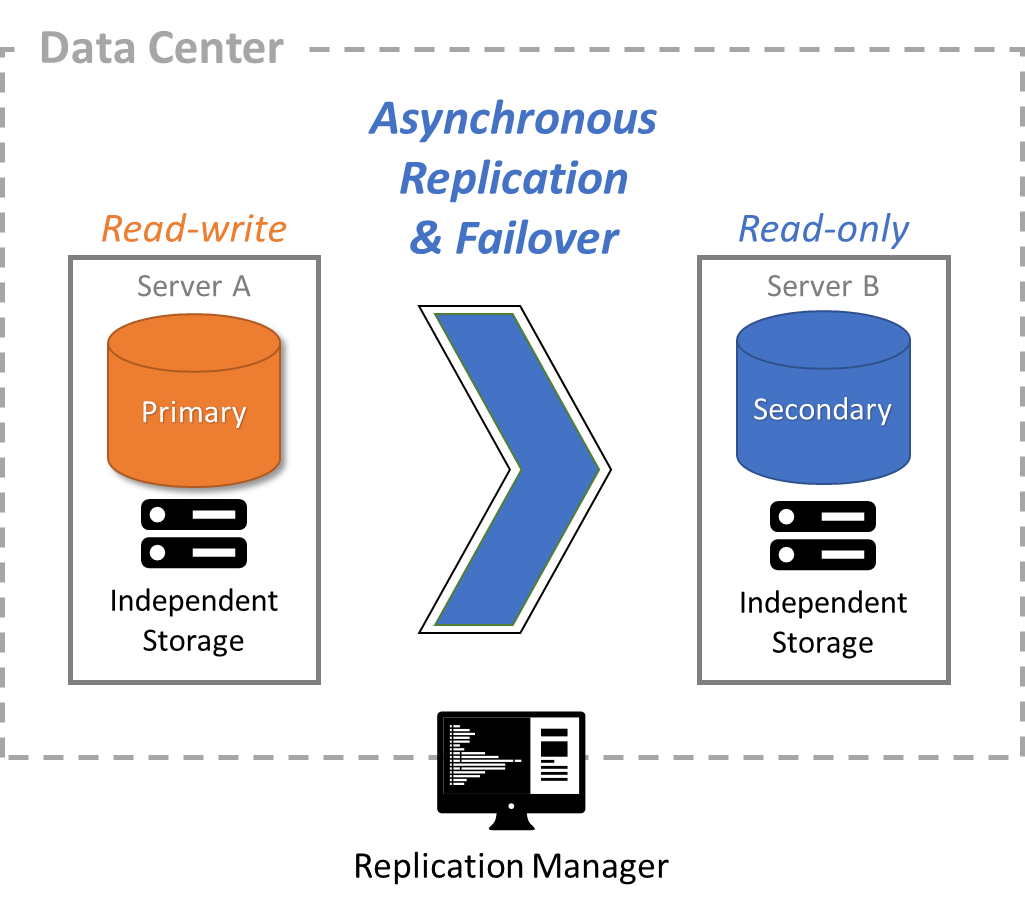
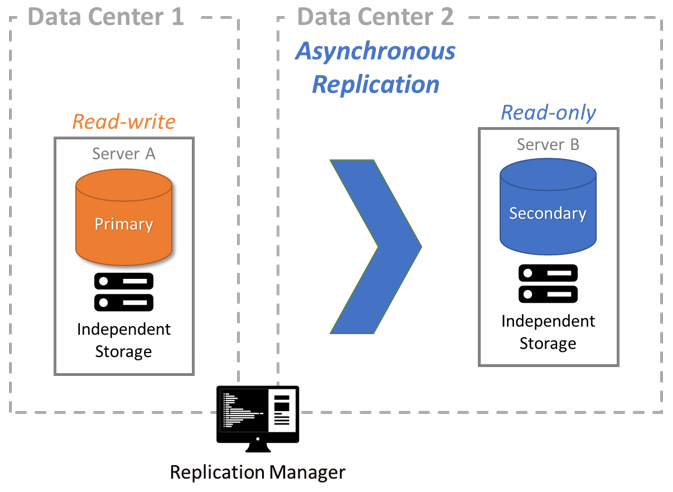
FairCom Replication makes it easy to create a read-only copy of your data with minimal performance impact. The data in the read-only copy may be slightly behind the primary server because of network latency.
Why:
Scale an application by running reports and analytics on additional servers without impacting online transactional operations on the primary server
Create a live, read-only copy of your data for quick recovery
Replicate data to a geographically distant region for centralized data warehousing, reporting, analytics, machine learning, etc.
How:
Use asynchronous replication to replicate an entire database—or a subset of it—to another server
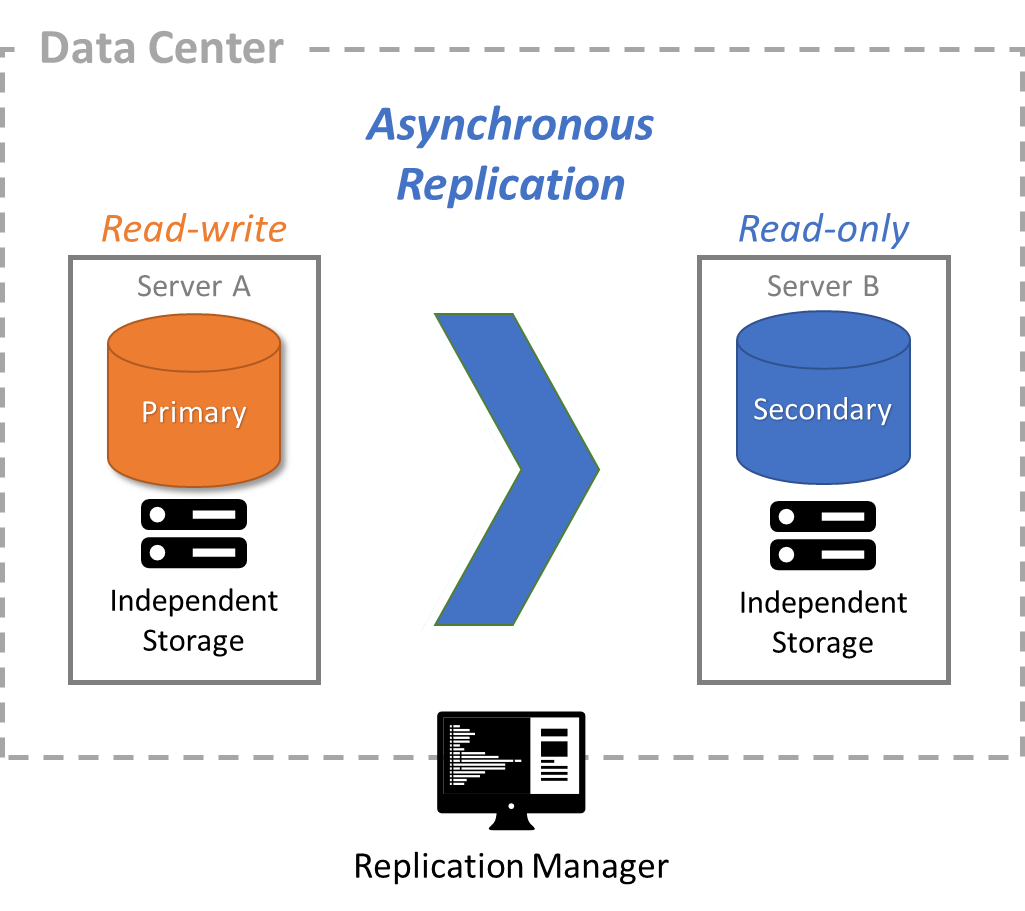
Continuously preserve an up-to-date copy of your data on remote servers.
Why:
Survive a disaster by preserving a live copy of your database in a geographically distant region
Quickly start up applications in the geographically distant region after a disaster because databases are always running with live, up-to-date data
How:
Use asynchronous replication to replicate your entire database to one or more servers in one or more geographically disperse data centers
Manually change the read-only replicas to become read-write primary servers when the primary data center is hit by a disaster
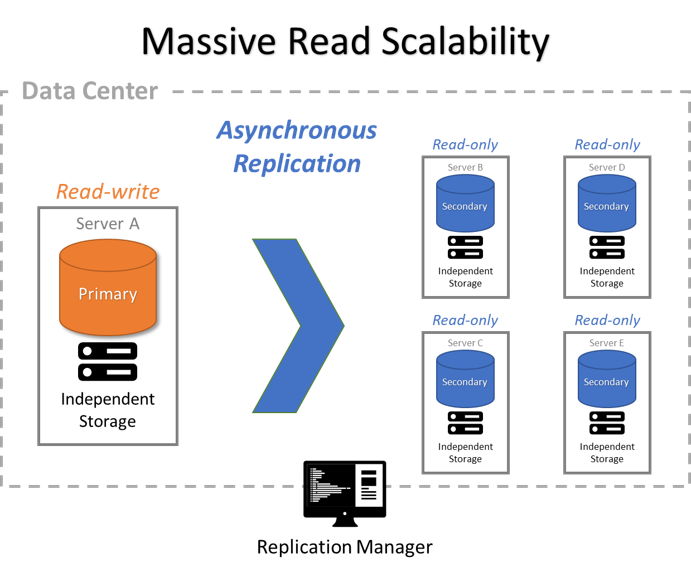
Global Distributed Read Scalability
Replicate an entire database or subsets of it across many remote servers and clients, horizontally scaling the data to support very large numbers of read-only users.
Why:
Scale read-only transactions across data centers, desktop apps, and mobile apps
How:
Use asynchronous replication to replicate the entire database to many other computers
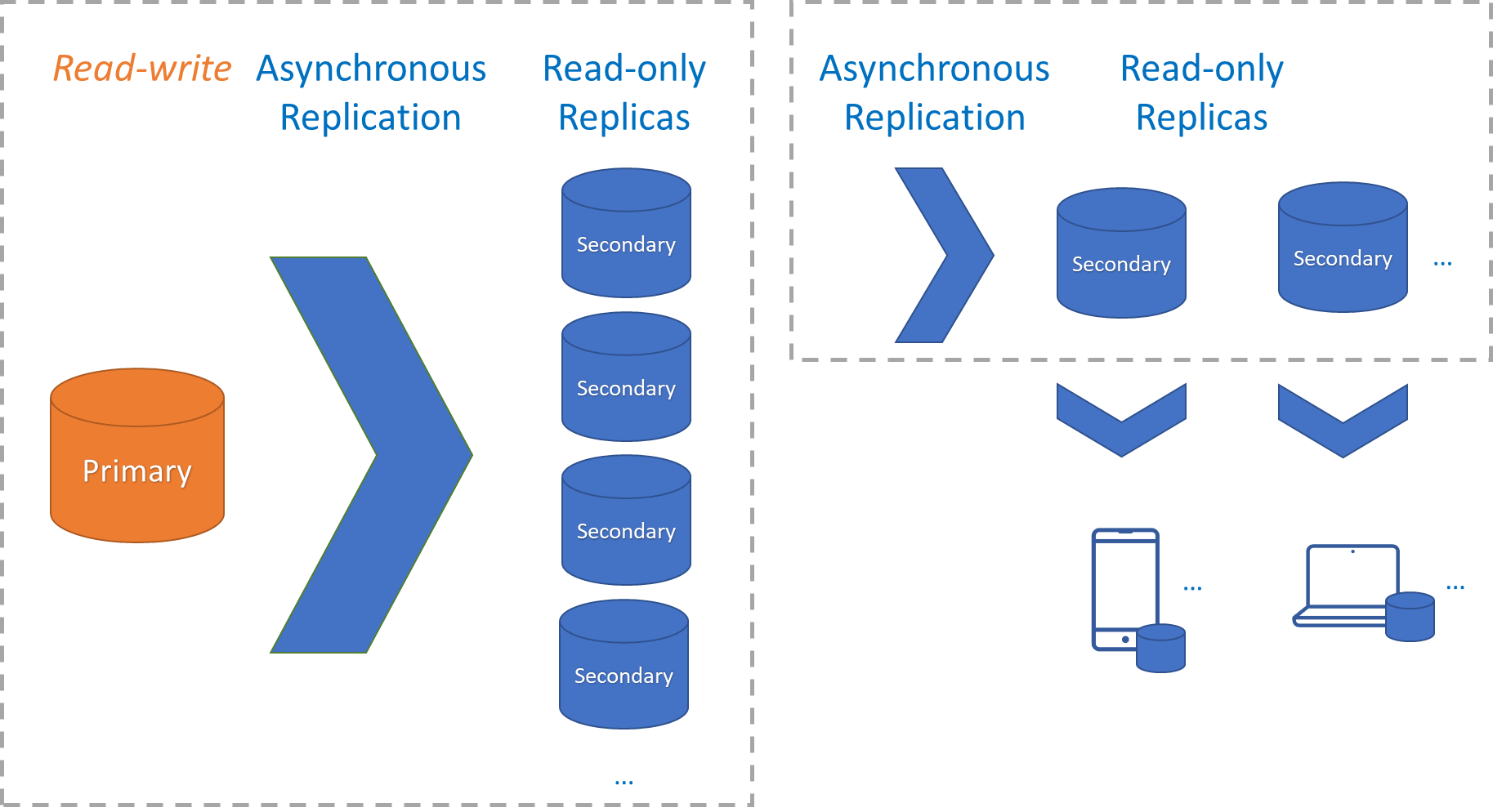
Chain asynchronous replication processes to achieve massive scale.
For example, replicate one server to twenty and then replicate each of those twenty to twenty more, and so forth. Doing this six times replicates data to 64 million computers.
Replicate subsets of data to each computer to minimize computer and network resources.
For example, replicate only a user’s working set of data to their mobile phone for quick, local, read-only access.
Selectively limit which data is replicated across data centers for regulatory compliance.
Why:
Government regulations require specific data to remain in country while requiring other data to be replicated across multiple countries
How:
Use selective asynchronous replication to replicate specific data in specific tables from one to many servers within and across multiple data centers
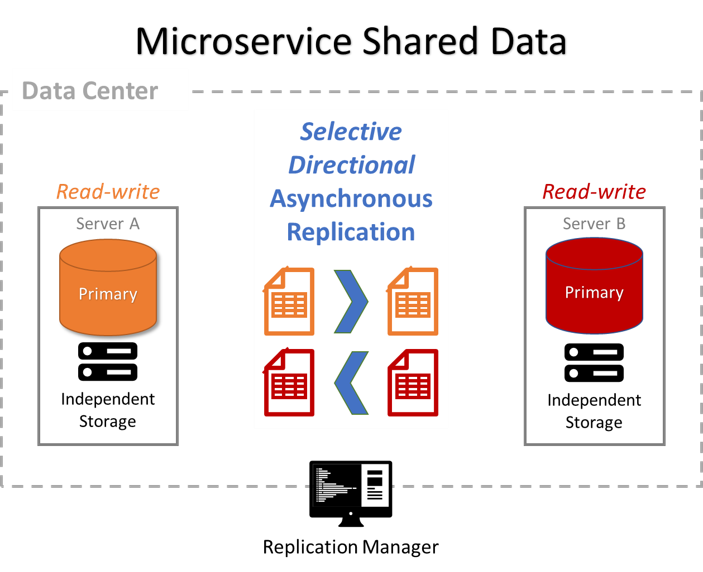
Microservice Shared Data
Avoid slow joins across microservices by providing each microservice with its own data.
Why:
Each microservice has its own dedicated database for independent upgrades
Each microservice needs selective master, lookup, and transactional data from other microservices because joins across microservices are slow
How:
Selectively replicate data across microservice databases
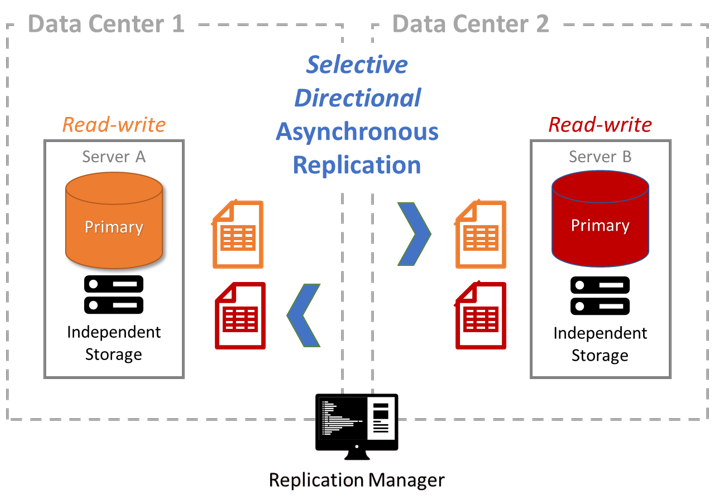
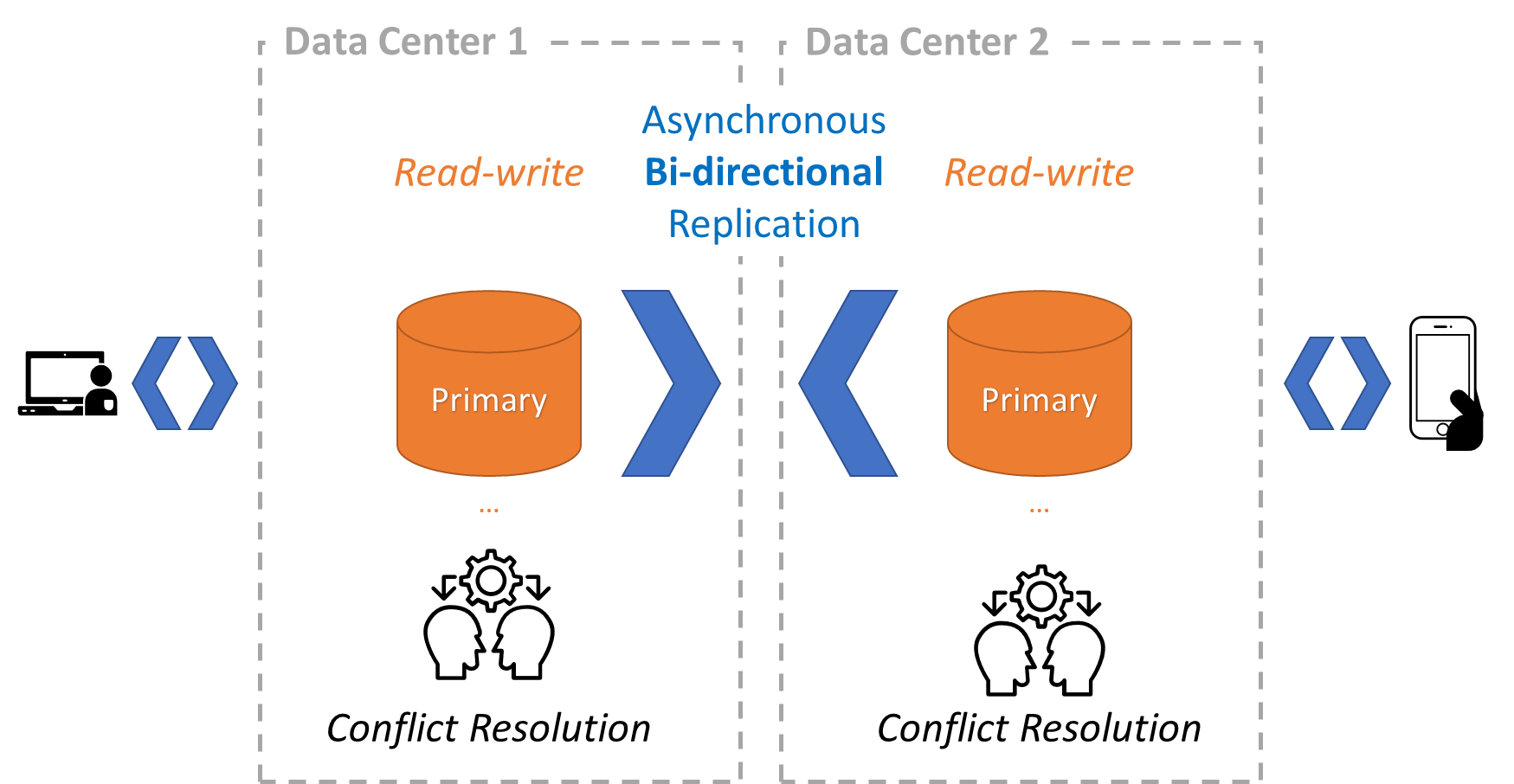
Eventual Consistency and Data Locality
Allow users to read and write data using data centers close to them for maximal availability and performance.
Why:
Allow users to read and write data to their closest data center for the following reasons:
Increases application performance because it minimizes network latency
Increases availability because it allows users to access other data centers for reads and writes when the closest data center is unavailable
How:
Use bidirectional asynchronous replication to replicate all data changes between servers
Use conflict resolution callbacks to deal with any data conflicts caused by simultaneous writes to the same data
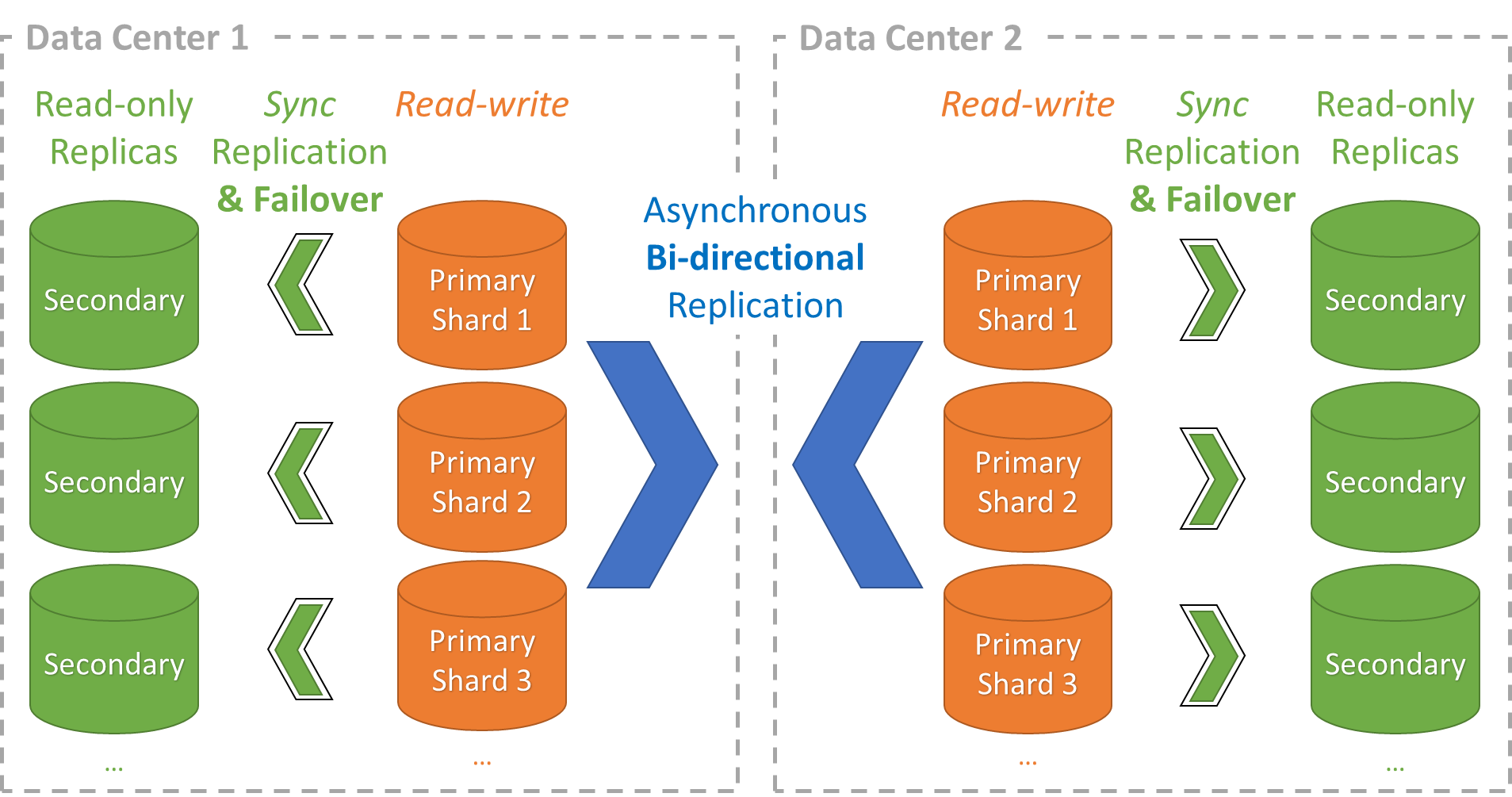
Sharded Data, Eventual Consistency and High Availability
Allow users to read and write data using data centers close to them for maximal availability and performance. Shard data for horizontal scalability. Lastly, provide high availability failover for each shard.
Why:
Allow users to read and write data to their closest data center:
Increases application performance because it minimizes network latency
Increases availability because it allows users to access other data centers for reads and writes when the closest data center is unavailable
Shard data across multiple servers to scale the application horizontally
Provide high availability for each shard to minimize downtime, increase data durability, and scale reads
How:
Use bidirectional asynchronous replication to replicate data changes of each shard across data centers
Use conflict resolution callbacks to deal with any data conflicts caused by simultaneous writes to the same data
Use synchronous replication to replicate each shard in each data center to a secondary server
When a primary shard fails, use automatic database failover to fail over to its secondary shard
Store the shard data boundaries in a table and replicate that table across all data centers
Use the FairCom Replication API in the application, which makes it easy to connect simultaneously to all shard database servers. Its remote-control ability makes it easy and fast to process data in all the shard database servers as if they were a single database. It makes it easy to use the shard data boundaries table to determine which shard holds the desired data and simply switch to it before processing its data.