|
|
|
The next chapter provides use cases designed around these new capabilities to maximize High Availability (HA) and Disaster Recovery (DR). We start with a quick introduction to HA and DR, and then provide several FairCom Replication use cases in the next chapter.
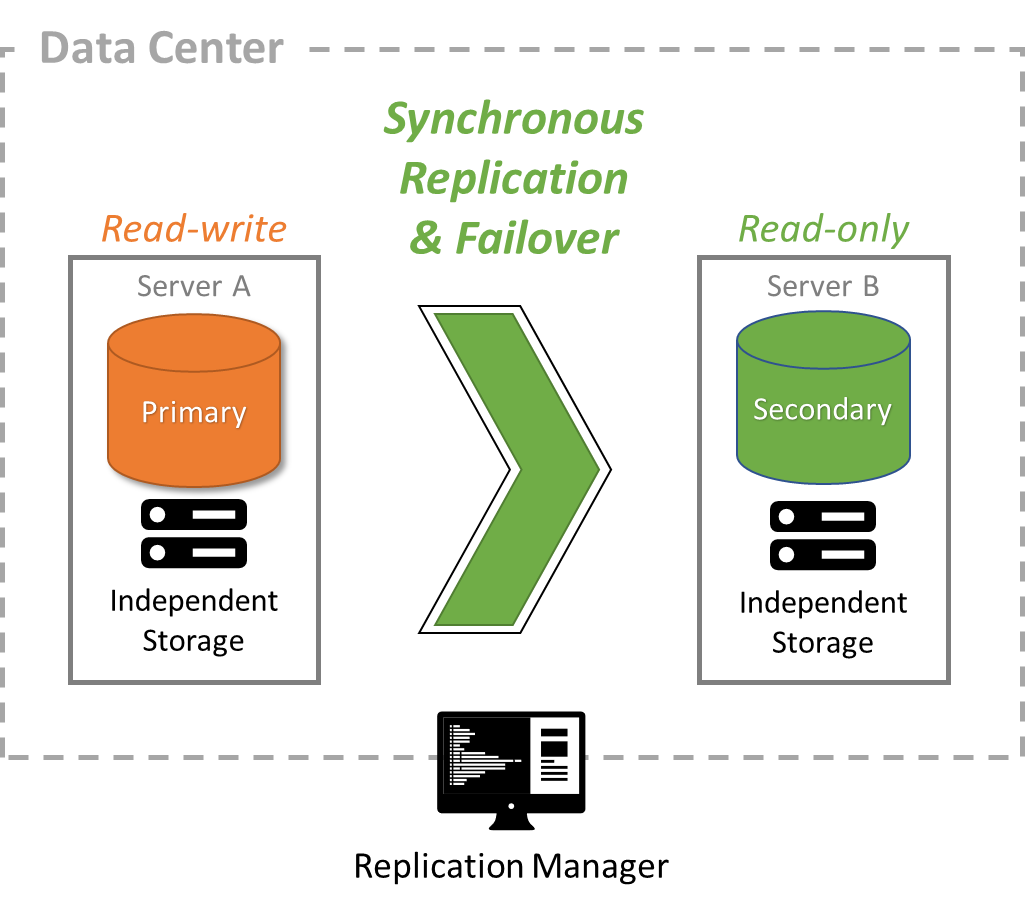
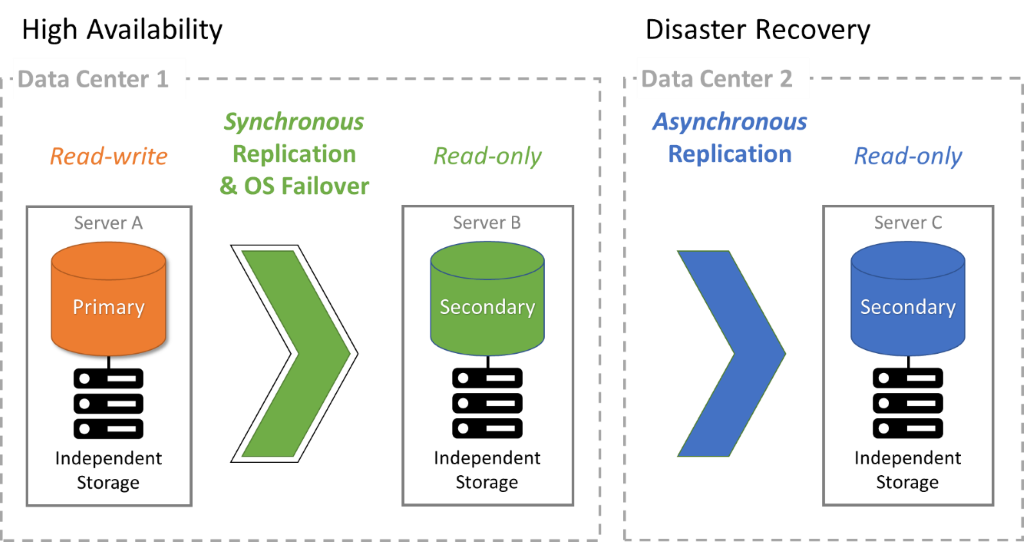
High Availability (HA) is the ability to remain available with no interruption to service during a system outage. Its purpose is to provide uninterrupted access to an application over a long time. It requires at least two servers running on different hardware. It optionally uses redundant hardware on each server and may run servers inside of virtual machines that automatically and transparently move off failed hardware servers to working hardware. It also requires mechanisms to detect software or hardware failure as well as mechanisms to ensure that a failed server remains down so that it does not process data unexpectedly and create data inconsistencies. Lastly, it provides mechanisms to automatically fail over database software and notify client applications to reconnect to the proper running database server.
FairCom’s fall 2020 release provides integration with Linux and Windows OS failover solutions as well as its own database failover solution.
Disaster Recovery (DR) is the ability to recover from a catastrophic regional failure in a few hours or a few days. Its purpose is to recover from a disaster by running an application in a different geographical region. This requires databases to be running in multiple data centers in different regions. The databases replicate data continuously from one region to another.
FairCom has provided asynchronous replication for many years, which is the ideal solution for this use case.
FairCom now allows an application to combine DR with HA, which gives applications maximum resiliency.
Learn more...
For more information about the use cases for FairCom replication, see Use Cases for FairCom Replication in Clustering for Scalability and Availability.

