|
|
Developer's Guide |
|
Clustering for Scalability and Availability |
|
Audience: |
Developers, Architects |
Subject: |
An overview of the FairCom replication options, including links to the necessary documentation |
Copyright: |
© Copyright 2024, FairCom Corporation. All rights reserved. For full information, see the FairCom Copyright Notice. |
This concept guide will help you understand and create clusters of FairCom Database Servers for scalability and availability.
Learn More:
See also:
|
|
Most databases implement fixed clusters that intermingle scalability with availability. This limits what a database can do and where it can be used. The need to scale data is independent from the need to make data highly available. These separate needs are best implemented as separate technologies that are designed to be combined in flexible ways.
Instead of a one-size-fits-all cluster architecture, the FairCom Database Engine allows you to create clusters to meet your exact needs for scalability and availability. It provides three technologies for this purpose:
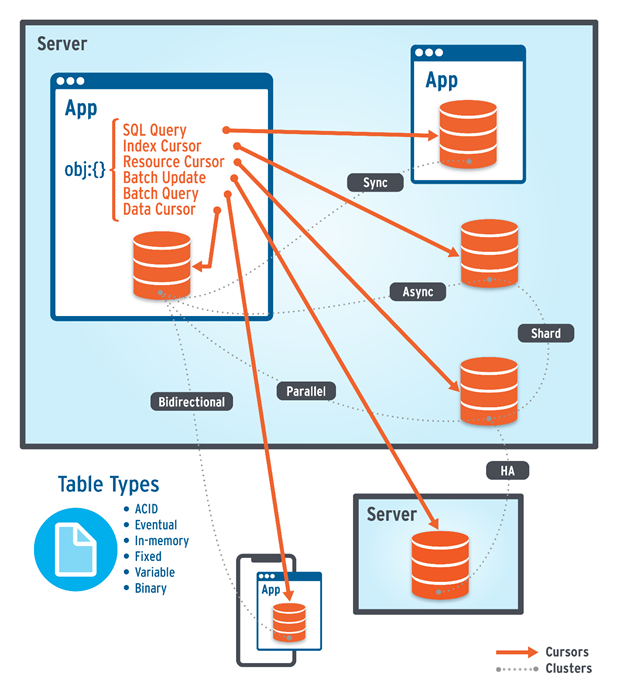
Replication Manager provides a browser-based graphical user interface that makes creating clusters a simple point-and-click experience. The Replication and Failover Engines are built into the FairCom Database Engine, which means they are automatically installed and ready to replicate data to any FairCom server as well as detect failures and automatically fail over to designated servers.
The following features are key to creating a cluster that meets your needs for scalability and availability:
|
|
Data replication uses one or more threads to replicate data at high speed while ensuring transaction order. It works asynchronously or synchronously. Asynchronous replication is ideal for replicating data within data centers for horizontal scalability. It is also necessary for replicating data across data centers for global availability and/or for deploying eventually consistent, write-anywhere solutions. Synchronous replication is best for implementing High Availability within a data center. You can combine synchronous and asynchronous replication to create all types of clusters, from Cassandra’s masterless eventually consistent cluster to SQL Server’s Always On ACID-compliant cluster and everything in between.
Replication occurs at the data file level. In the FairCom Database Engine, a data file is a SQL table except that records in a data file can be much more complex than flat tabular data. Replicated data can be filtered to replicate subsets of data within a data file. Replicated data files can be read-only or read-write. Replication can also be bidirectional or one-way. Bidirectional replication is integrated with automatic conflict detection and resolution. All changes to data are replicated, including replicating newly created, altered, and deleted data files, schemas, records, indexes, etc.
Servers can also be configured to detect failures and fail over automatically to one or more designated servers.
This flexibility allows you to implement any scenario including ACID-consistent high availability, eventually consistent high availability, disaster recovery, massive horizontal scale (read-only or read-write), globally distributed data (read-only and read-write), global regulatory compliance, shared data across microservices, etc. Later in this guide, we will show you how to combine replication and failover to implement these use cases.
To make it easy to create and manage clusters, Replication Manager provides a graphical user interface that makes it easy to publish groups of data files and subscribe to multiple publications.
Replication Manager runs in a central location and automates replication across many FairCom database servers. It consists of a browser-based graphical user interface, an application server, and a built-in database. It installs easily and quickly by simply unzipping into a folder and running the executable. Once you register FairCom servers with it, Replication Manager automates all replication tasks across all servers with a simple point-and-click interface.
|
|
Synchronous Unidirectional Replication is needed for ACID-compliant mission-critical environments. It ensures data is replicated before returning a commit to the application. This eliminates data loss and out-of-sync data. All data is always consistent at a point in time.
Asynchronous Bidirectional Replication with Conflict Resolution is needed for eventually consistent mission-critical environments that allow the application to write anywhere for maximum local performance and local availability. The data is eventually (but quickly) replicated across the cluster. Conflicts are automatically detected, and the application is notified so it can appropriately resolve them.
Asynchronous Parallel Replication is needed for horizontal scalability within and across data centers. You can use it to create read-only servers that have point-in-time consistency or you can create eventually consistent read-write servers.
Selective Asynchronous Replication is needed for sharding data across servers. FairCom’s NAV APIs make it easy to remote control many databases at the same time. Your application can use any sharding algorithm to write and read data across shards. Selective replication can automatically use the same algorithm to ensure that data is replicated properly to the desired shards.
Parallel Replication uses multiple threads to replicate data in parallel while ensuring transaction order. This makes replication much faster than serial replication. It often executes replicated transactions on the target server faster than on the source server. You control the level of parallelism to match the capabilities of your CPU. You can add parallel processing to synchronous and asynchronous replication. In both cases, replication honors the order of dependent transactions to ensure full ACID compliance.
Serial Replication is desirable when increased performance is unnecessary, when CPU is needed elsewhere, or when ensuring transaction order in parallel replication is slower than simply using serial replication.
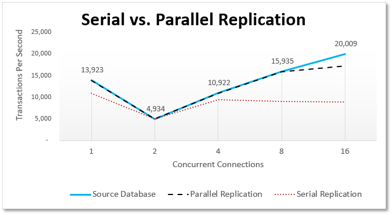
In the diagram above, Serial Replication starts falling behind at 4 concurrent connections. Parallel Replication keeps up with the source until it reaches the maximum threads assigned to replication. In the illustration above, replication was assigned 8 threads; thus, replication performance starts falling behind when 16 processes are updating data concurrently.
|
|
OS Clusters, Failure Notification, and Synchronous Replication - High Availability (HA) is the ability to remain available with minimum interruption to service during a system outage. You now combine synchronous replication, failure notification, and OS clusters to implement high availability without licensing and installing a complex clustered file system. Because the storage is not shared, the cluster has higher availability. This solution is supported on RedHat Enterprise 8 and Windows Server. It is a highly available, ACID-compliant cluster with automatic failover and no possibility of a split-brain scenario. This is an active-passive solution where the secondary servers are not available to process transactions until failover occurs.
FairCom Failover (BETA) with Synchronous Replication - FairCom can detect server failures and automatically fail over to designated servers. Database servers replicate from a primary read-write server to one or more read-only servers. If the primary server fails, it automatically fails over to one of the read-only servers. It creates a highly available, ACID-compliant cluster with automatic failover that is partially active-active because read-only servers are available for read-intensive operations across servers, such as batch reporting, analytics, and machine learning. The cluster automatically and transparently directs write operations to the primary server and directs read operations to the read-only servers. The cluster detects failures and automatically fails over to an available server -- completely transparent to the application.
FairCom Failover (BETA) with Asynchronous Replication – This works the same as the previous scenario except that asynchronous replication allows the primary server to replicate data to many servers – including servers in the cloud and remote data centers. It has the downside that network latency introduces a slight risk of losing some data during a failover event. The cluster detects failures and automatically fails over to an available server -- completely transparent to the application.
The flexibility of this architecture makes it easy to:
|
|
Windows High-Availability Cluster
FairCom technology has always been able to be used in conjunction with Windows Server versions that include operating system cluster support. FairCom has enhanced this integration starting with V12 by including client-side notification technology to simplify this integration. The following book is a how to book detailing setting up a highly available Windows Cluster using FairCom DB Technology. This same process will work with c-treeRTG and FairCom Edge.
See High Availability Using Windows
Linux High-Availability Cluster
Similar to Windows, FairCom technology has always been able to be used in conjunction with Linux operating system versions that include operating system cluster support. FairCom has enhanced this integration starting with V12 by including client-side notification technology to simplify this integration. The following book is a how to book detailing setting up a highly available Linux Cluster using FairCom DB Technology. This same process will work with c-treeRTG and FairCom Edge.

