|
|
|
Transaction control by definition requires logging all database changes to persisted storage. Of course, transaction control is highly desirable for recovery of the database in the event of system failure. It also makes available other valuable features such as replication. However, this comes with a direct and measurable performance cost.
The new Delayed Durability feature can greatly enhance performance; however, should a system fail, database recovery could take considerable time if the transaction logs held substantial volumes of data not yet flushed to data and index files.
This leads to an additional challenge of how to balance data integrity using transactions against performance and recovery. Certain classes of applications can restore to known points in time. Consider the simple case of a bulk load. Should anything fail during loading, the load process can usually be restarted. If this known position could be coordinated with a c-treeACE server transaction log position, one could architect a very effective recovery process.
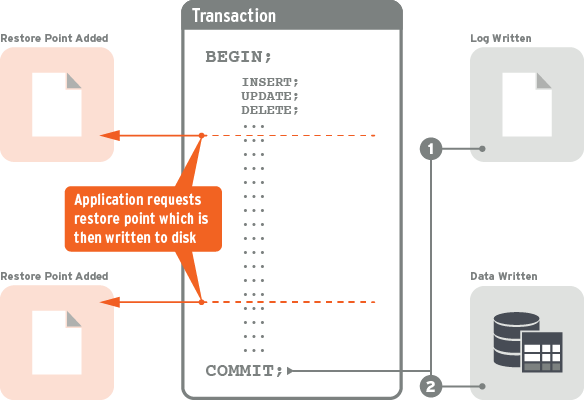
To this end, a new Restore Point feature has been introduced. A Restore Point is a position in a transaction log to which FairCom Server’s automatic recovery can roll back the system in event of system failure.
The Restore Point is used for restoring a system to a point in time coordinated with the application as a known good state. After restoring the system to a Restore Point, the application can be architected to perform work that was not recovered. For example, those applications maintaining their own journal of operations. By coordinating a known good state in time between the application and the server’s transaction logs, these applications can quickly recover back to a point in time when absolutely needed.
See Transaction Restore Points for Application Recovery.
Lightweight vs. Checkpoint Restore Points
By reducing the need to sync the transaction log to disk, this new transaction processing mode can improve performance substantially. The tradeoff is that automatic recovery is not guaranteed to make good on all the committed transactions. To make recovery predictable and usable, we introduce the concept of a Restore Point (RP). A Restore Point is a place in a transaction log that has no active transactions. Two types of Restore Points are available:
Every N minutes (where N is a small number), the application will issue a lightweight checkpoint, and before restarting transactions, start an external activity log. If a crash occurs, it is possible to recover to the last Restore Point, and redo the activities in the external log.
A Checkpoint Restore Point provides a clean place in the log where roll forwards from a Dynamic Dump can stop and restart. Imagine that a system in operation runs a complete dynamic dump, and then periodically (each hour, each day, etc.) issues a Checkpoint Restore Point. A backup system can be maintained in fairly up-to-date fashion by using the Checkpoint Restore Points as convenient milestones to roll forward from and roll forward to.

