|
|
|
Scale UP to Enhanced Performance!
Commit Read Lock optimizations Advanced hash lookups speed filename searches Unbuffered I/O bypasses file system cache Faster numbering of transactions |
Reduced memory suballocator contention scalability Reader/Writer Locks enhance synchronization efficiency Numerous SQL query optimizations |
Range search optimizations Unix shared-memory connections Reduced index node contention Critical Section Spin Count optimizations on Windows |
Reduced file header reads Intelligent file open/close logic for increased efficiency of file handlers Improved PreImage search of transaction hash entries |
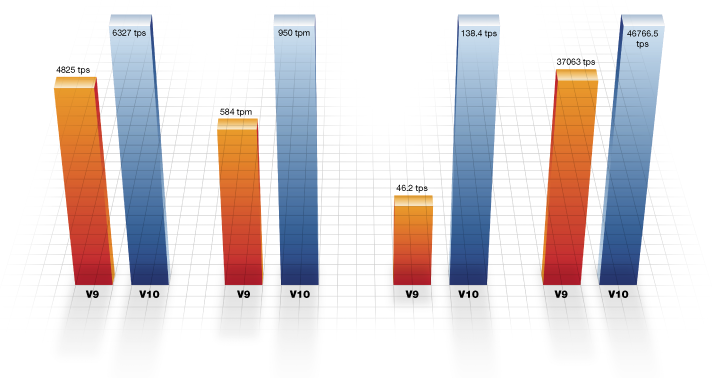
30% Faster Transaction Throughput |
60% SQL Performance Improvement |
200% Better Replication Throughput |
26% Faster Read Performance Testing |
Test Environment: |
Test Environment: |
Test Environment: |
Test Environment: |
• 100 threads |
• 20 threads |
• 100 threads |
• 100 threads |
• Hardware: Dell PowerEdge, 16 Cores, 3.6 GHz, 32 GB RAM, Seagate ST3600057SS SCSI Hard Drive, 2 X 600GB, 15K rpm |
|||
The considerable performance gains experienced with the V10 release are a result of astute profiling of the c-treeACE database engine internals. Scalability issues, bottlenecks, contention points, wait times, capacity sizes, as well as many other details were wholly critiqued through thorough profiling, testing, and extensive benchmarking. Additionally we encouraged and considered “real world” feedback from customers. We are excited with the results and encourage you to adopt this V10 technology as soon as possible and experience these rewards.
Later in these notes, the Foundations of V10 Performance Gains section details the significant internal improvements within the c-treeACE core engine. Many are low-level internal changes and the combination of all these improvements resulted in overall higher c-treeACE performance with much improved scalability. The highlights are summarized below. The internal details are most applicable to those who wish to understand the depth behind the significant performance improvements in V10.
FairCom has subjected our latest releases to extensive testing in areas of scalability and performance to leverage technological advances in today’s operating systems and hardware platforms. We have achieved significant internal core engine performance improvements in the areas listed below.
Synchronization Objects - Semaphore/Mutex:
Transaction Processing:
File I/O:
Memory:
Locking:
More Advances:
Need more proof? For a detailed list of the development work we have done to bring you enhanced performance, see the section titled Foundations of V10 Performance Gains.

