|
|
Concepts Guide |
|
FairCom Database Engine Partitioned Files |
|
Audience: |
Developers |
Subject: |
Using the FairCom Database Engine Partitioned Files feature to manage large databases comprising multiple files |
Copyright: |
© Copyright 2025, FairCom Corporation. All rights reserved. For full information, see the FairCom Copyright Notice. |
|
|
|
|
Many applications collect continuous data that goes out of scope within a period of time. Common examples are time based log and auditing data and even financial transactions. When this data is stored in a very large file, removing bulk portions is time consuming, generally requiring an operation such as the following
delete all data where key value older than target
An alternative is to store associated data sorted into key ranged data files. That requires application processing of new files and dropping old files, while keeping file naming on disk unique. This technique is classically known as sharding.
A better approach is a specialized data file that can be accessed as a single file, and automatically physically partition data based on a single key allowing rapid data management. This FairCom DB feature is termed Partitioned Files.
Applications requiring rapid purging of large data ranges is the target audience for this feature.
|
|
We described the most common use case of purging data. However, partitioned files can take this to another level as data doesn't have to be just deleted. Data partitions can be marked "offline" and archived for long term storage. This allows large volumes of data to be quickly removed and stored in alternate locations. Archived partitions can later be "reactivated" for searching when needed.
|
|
A partitioned file is composed of a host data file and its associated indexes combined with a rule. The rule determines how to map the partition key value (e.g., a date, or invoice number, or some other characteristic) into a particular partition member of the host. The host file does not contain any actual data, but serves as a logical file that appears to contain all the data.
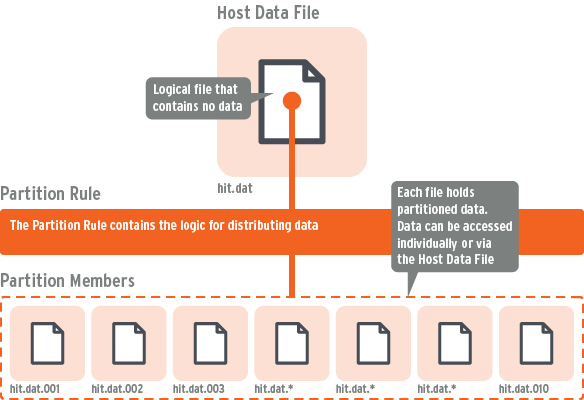
A partition member file has the same definition as the host, but only holds data whose partition key maps to the member. For example, customer orders may be partitioned by calendar quarter. All orders booked in the same quarter are stored in the same member. A member is composed of a standard c-tree data file and its associated indexes.
To add data to the partitioned file, simply call an add routine for the host. The code will add the record in the proper partition member, creating the partition member if necessary. Rewriting a data record may move the record between partitions if the partition key entry for the record is changed. Under transaction control, such a delete/add record operation is done atomically.
Searching the partitioned file in key order is fairly straightforward and efficient if the key is the partition key (the key used to determine which partition should contain the record). Searches on other, non-partition, keys are less efficient than normal because the record may exist in any of the partition members. The more active partition members there are in the logical file, the less efficient the non-partition key search will be.
It is possible to manage the partition members so that archiving or purging partitions is very quick and efficient.
|
|

