|
|
|
FairCom DB API, a name for the "c-tree DataBase", represents a high-level, easy-to-use API on top of the FairCom DB ISAM and FairCom Low-Level APIs. FairCom DB API is intended as the standard for c-tree programming. This API makes the developer's life easier without removing the flexibility and performance of the original APIs.
The FairCom DB API general architecture is presented in the figure below, organized into seven different levels: session, database, table, field, index, segment, and record. These levels or layers will be used to present a group of common functionality.
It is important to note that c-tree data and index files can be manipulated directly with or without session or database dictionary support. Please refer to the Working with Sessions without Dictionary Support and Allocating a table handle without database support for more information.
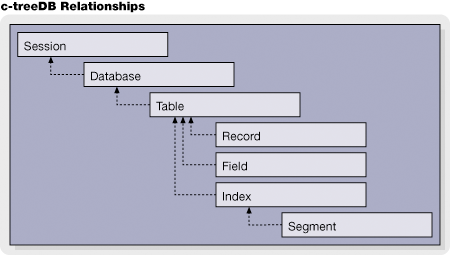
A session represents a connection between a client and a c-tree Server and some configuration information on the Server. No work can be performed before a session becomes active. The session handle indicates the FairCom DB API session, the server name and location, the directory where the databases are located on the server, and the user name and password.
A database can be considered as a collection of tables, and each database has its own database dictionary that stores information about each table that belongs to that database such as the table name, password and path, the active (open) tables, and the number of tables linked to the database. The database handle indicates a database in the session and each session can have multiple databases.
A table is essentially a c-tree Plus data, and optionally, index files. There can be, and typically are, more than one table in a database, and a given table may belong to multiple databases. A Table may have zero or more records.
A field is the basic element of a table, and a collection of fields forms a data record.
Often a table will have zero or more indexes, which enhances the retrieval of records from that table.
Indexes typically have one or more segments describing the index key structure. The index handle indicates an index associated with a particular table, while the segment links the index with the fields.
A record is essentially an entry row in a table. A record handle indicates a record instance on a particular table. A table may have one or more record handles associated with it. Each record handle can be used as an independent cursor into the table, which implements the concept of a "current record" in the table. The table can then be traversed by accessing the "next record" or the "previous record" in the table, or by directly jumping to the first record, or by using a find operation to locate a specific record in the table.

